Language Translation Issues

프로그래밍 언어 정의
: 구문(Syntax) + 의미(Semantics)
구문 (Syntax)
: 어떻게 생긴 것이 제대로 생긴 프로그램인가에 대한 것
의미 (Semantics)
: 제대로 된 프로그램은 어떤 동작을 하는지에 대한 것
구문 표기법
BNF (Backus-Naur Form)
: Type 2 문법(Context free grammar)을 표현
- 비 단말 기호 (Nonterminal)
- 아직 완성되지 않은 부분
- 다른 형태로 치환 가능한 기호(변수)들의 유한 집합
- 꺾은 괄호(angle bracket)로 감싸서 나타냄
- <sentence> | <subject> | <predicate> | <verb> | <article> | <noun> | ...
- 단말 기호 (Terminal)
- 문법에 의해 실제로 나타나는 글자나 단어
- 더 이상 치환할 수 없는 기호(상수)들의 유한 집합
- 그냥 쓰거나 따옴표로 감싸서 나타냄
- the, boy, girl, ate, cake, ...
- 시작 기호 (Start Symbol)
- 특별히 정의된
하나의 비단말 기호- <sentence> | <S>
- 특별히 정의된
- 생성 규칙 (Productions, rewriting rules)
- 각 비단말기호를 어떻게 바꿔 쓸 수 있는지에 대한 유한 개의 규칙
- <sentence> ::= <subject> <predicate>
- <subject> ::= <article> <noun>
- <predicate> ::= <verb> <article> <noun>
- <verb> ::= ate | ran
- <article> ::= the
- <noun> ::= boy | girl | cake
- 각 비단말기호를 어떻게 바꿔 쓸 수 있는지에 대한 유한 개의 규칙
- 치환 연산 (Replacement Operation)
- 비단말기호를 생성규칙에 따라 바꿔 쓰는 것
=>기호로 나타냄- <article> <noun> <predicate>
=>the <noun> <predicate>
- <article> <noun> <predicate>
Syntax doesn't imply correct semantics
문법적으로 올바르다고 해서 반드시 의미가 통하는 것은 아니다
EBNF (Extended BNF)
: 기존 BNF의 ::=, | 기호 외에도 [], ( | ), { }*가 추가(확장)된 문법
- [] - 있어도 되고 없어도 됨 (0회 또는 1회)
- ( | ) - 안쪽 or 기호들 사이에서 선택 (반드시 하나 선택)
- { }* - 0번 이상 반복 (0, 1, 2, ...). []와 비슷하지만 반복도 가능
CFG (Context Free Grammar)
: 어떤 nonterminal이 들어와도, 그에 대한 생성규칙이 존재하는 문법
- BNF보다 짧고 간결하게 표현 가능
- BNF: <A> ::= <B><C>
- CFG: A -> BC
BNF, EBNF, CFG의 표현력(표현 가능한 범위)은 같다!
- Static Semantics
- CFG로 나타낼 수 없는 범위의 구문을 규정함
- Attribute Grammar로 표현됨
- 경우에 따라 Semantics의 범주에 포함시키기도 함
의미 표기법
Denotational Semantics
: 프로그램의 의미를 semantic function을 통한 evaluation으로 해석
Operational Semantics
: 프로그램의 의미를 state transformer로 해석 - 이때 state는 machine state를 나타냄
Axiomatic Semantics
: 프로그램의 의미를 predicate transformer로 해석
의미론은 살짝 난해한 분야임..!
번역 과정
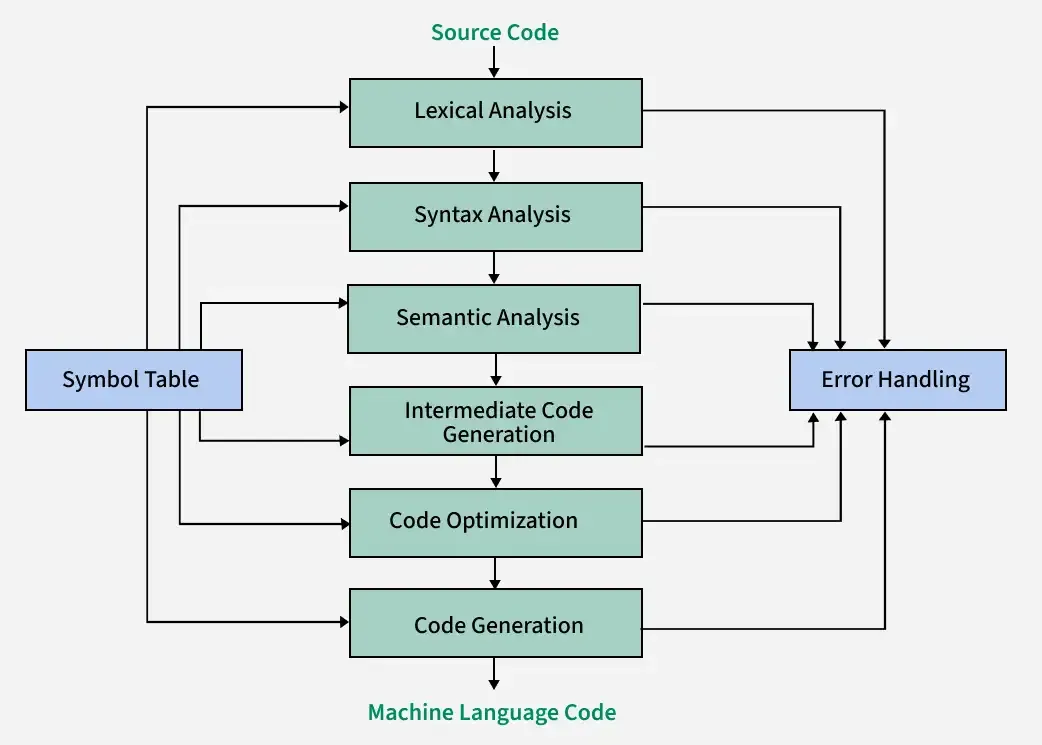
- 어휘 분석 (Lexical Analysis, scanning)
- 프로그램을 단어로 나눔
- 주석 제거
x := a * 2 + b * (x * 3)
-> id<x> assign id<a> times int<2> plus id<b> times lparen id<x> times int<3> rparen- paren = parenthesis
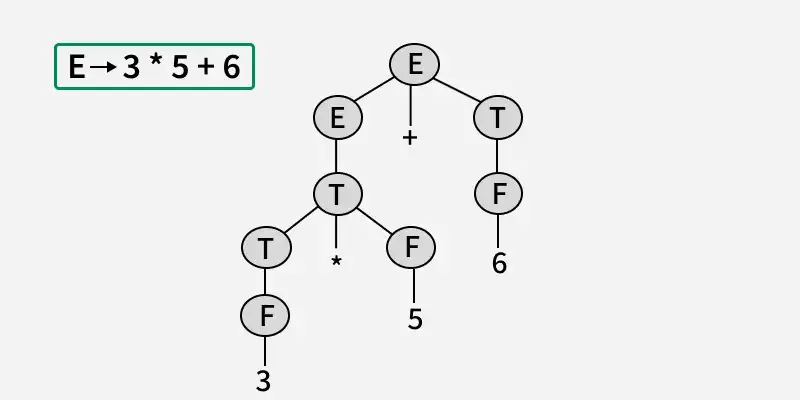
- 구문 분석 (Syntax Analysis, parsing)
- 구문 구조를 tree로 표현
==parse tree생성
- 의미 분석 (Semantic Analysis)
- 정적(Static) 의미 분석
타입 검사는 여기서 수행- 변수들이
사용되기 전에 정의되었는지도 검사
- 중간 코드 생성 (Intermediate Code Generation)
- parse tree로부터 수행 가능한 코드를 생성
r1 <- load M[fp+x]
r2 <- loadi 3
r3 <- mul r1, r2
r4 <- load M[fp+b]
r5 <- mul r3, r4
r6 <- load M[fp+a]
r7 <- sll r6, r5
r8 <- add r6, r5
store M[fp+x] <- r8- 최적화 (Optimization)
- 코드의 동작을 유지하는 선에서, 각종 성능을 개선
- code size
- registers
- speed
- power
- [기계어] 코드 생성 (Code Generation)
모호성 (Ambiguity)
: 어떤 문법에서는 같은 문자열에 대해서 두 개 이상의 파스트리가 얻어질 수 있다.
== 파스트리가 유일하지 않다 == 문법이 모호하다
- 모호성을 제거하려면?
- 문법 자체의 모호성 제거함
- 파서에서 특정 파스트리만을 선택하도록 함
문법적 모호성 제거하기
S -> SS | (S) | () 는 S -> SS 부분에서 모호성이 생길 수 있다.
예를 들어, ()()()를 생성할 때 S => SS => SSS로 가는 과정에서 두 가지 파스트리가 생길 수 있다.


